 Shokunin Consulting LLC.
Shokunin Consulting LLC.
Blog Devops notes
Operations tools setting up for a win
2013-02-16 00:00:00 -0800
One thing I have learned consulting at companies is that with the proper building blocks (update/original) in place, it is possible to avoid outages, improve end-user experience and motivate developers.
Quite often operations tools such as monitoring and analytics are useful for noticing problems with the infrastructure and applications, but with the proper usage and communication they can add value to an organization in many ways.
Case study
Under pressure to release a new feature, developers rush to migrate an application to a new framework that has not been run in production before. After testing carefully and working with the Ops team the new version is released on Friday by the Ops team while a Dev team member is present. Everything seems to run smoothly and the team heads off to enjoy a much deserved weekend off.
Because the Ops and Devs had worked closely to develop monitoring procedures before the release, the Ops team notices that application servers are occasionally hanging and setting off alarms in monitoring (Icinga). These clear quickly as the automated process manager (Monit) kicks in to restart the application, before the issue can be perceived by end users.
Since the entire infrastructure is under full configuration management control (Puppet) there is no back and forth between groups about things changing in the infrastructure. The system manifests are all under source control management (Git), so infrastructure changes are easily visible. In addition, the Ops team has a policy of no changes on Fridays. Due to the factors, the infrastructure as a culprit can be quickly ruled out and it is possible to quickly focus on the application layer.
The Ops team has been given the resources to spend on collecting data on all facets of the environment including OS level performance statistics (Graphite/Collectd). From the graphs it was easy to determine that the number of connections to the application was growing steadily and not being released. This was easily confirmed by checking a single application server that showed the high connections in the graph.
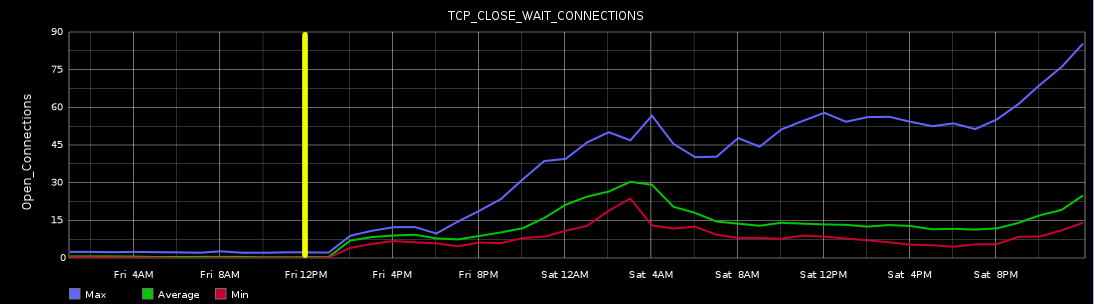
The Ops team dashes off an email to the Dev team member assigned to the release detailing the issue, with graphs to illustrate the issue and some logs from the centralized log service (Logstash) to provide additional background. Then the Ops team decreases the thresholds for application restart to mitigate the issue, while the Developer searches for the issue.
Since the developer has a clear picture of what the issue is and has data to indicate that the change happened after the latest release, he is more easily able to track down the root cause quickly and determine the fix. Because he has worked closely with the Ops team, he does not consider the job done on the code change, but works with the Ops team to release the latest version of the software. Having done so, he can monitor the metrics in real time and see the effect that his change has on production. As a final step, the developer sends an notification with the following graph to clearly illustrate a solution's effect in production.
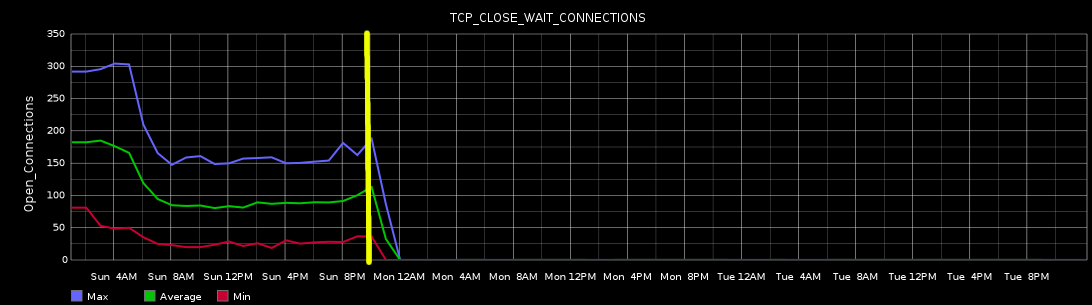
All of this occured before end users could perceive any issues.
Conclusion
This is how I believe SaaS companies should operate, but this was not entirely a matter of having the correct tools.
Several factors contributed to avoiding trouble.
- The Ops team had the resources to impliment the necessary instrumentation
- The Dev team made a resource available to spearhead the release process
- The Dev team has a culture of "it's not done until it is stable in production"
- Both teams had worked closely in the past and had the necessary respect for each other
- Data, not blame, was passed between groups making it easier to focus on finding a solution
- Tools provided near real time postive feedback, which eases inter-group tensions by clearly illustrating a win